Automating the clinical coding process in an NHS Trust

Where does one begin with a concept as potentially convoluted and byzantine as the automation of a clinical coding function within an NHS Trust? (I will henceforth refer to this function as ‘coding’, apologies to my programmer colleagues). How would you go about it…why would you bother? Questions well asked and ones I’ve considered more than once since starting my career in clinical coding eightish years ago.
This is the first in a (hopefully) series of blog posts where I will attempt to give form to my thoughts around the potential of automating coding…In truth this is also my first blog post…which I suppose at least gives me a ‘get out of jail free’ card should my musings be received poorly! Such is the grace granted to the ‘newbie’ and fie to those who say less.
As you read through this post I’d like you to just keep the NHSX five missions in the back of your head, actually three in particular as I feel they’re intrinsically related to this topic;
“Reduce the burden on our workforce, so they can focus on delivering care;
Ensure information about people’s health and care can be safely accessed, wherever it is needed;
Improve health and care productivity with digital technology.”
A bit of background to set the scene first may be beneficial and those of you who already know me please feel free to skim. Eight years ago I completed my academic studies in Biomedical Science, a proud alumnus of the University of Bedfordshire (exotic!) and rather than continuing my laboratory career happened upon an advert for an entry level coding position at Northampton General Hospital NHS Trust. Frankly I’m still not entirely sure why I did but I applied, was recruited and haven’t particularly looked back since. People talk of ‘dream jobs’ well…my career within this field has allowed me to put whatever strengths I have been granted in this world toward The Institution that is the National Health Service, at it’s core something I rather strongly believe in.
I’m now the Head of Coding at Kettering General Hospital NHS Trust working alongside some excellent colleagues including ian roddis, Andy Callow, Mary Macleod and Jaswant Singh Sagoo to name but a few. Whilst my focus has shifted toward the strategic and operational I still find coding itself rather interesting, perhaps to an embarrassing degree. But when I first joined this career path and indeed many times since then I’ve had frequent musings over the overall working process and its relative inefficiencies.
To help illustrate the manual coding process in a typical NHS Trust I’ve included Figure 1 below — forgive me those who already know this process and can see it tattooed even on their eyelids when they close their eyes but I thought this would be useful for a broad audience. I’ve included each major ‘stage’ in the process supported by descriptive text — you can see the coder is directly involved in stages 2, 3 and 4.
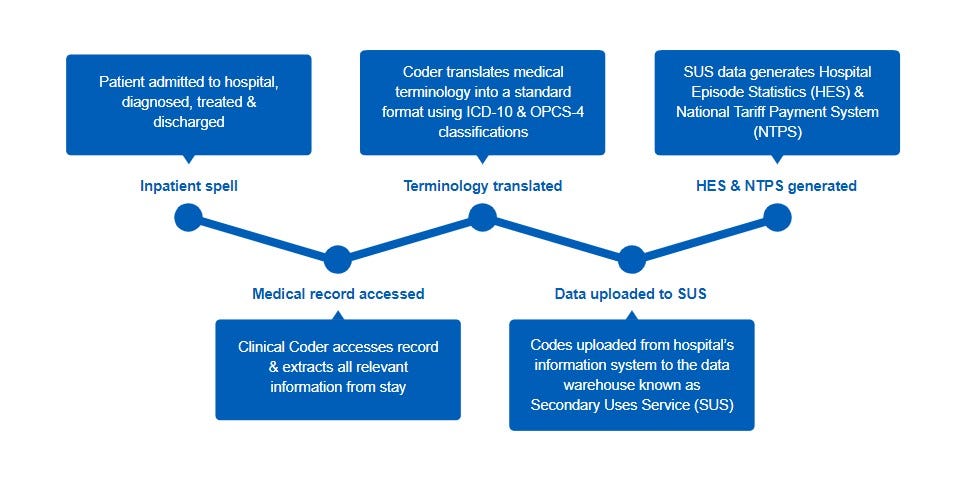
Now…the coder is a trained professional, valuable and time consuming to ‘create’. The typical timeline to establish one accredited coding professional is between three to five years depending on circumstance and the ability of their service to support them. The fruit of their labour, patient coded data, is variously utilised across the NHS in England and Wales for numerous statistical, financial and clinical purposes. Consider the output of a coder as one of THE primary representations of the health issues of our populace and the care that NHS Trusts provide to this populace. In short their output is quite important.
Given all of this then imagine me now as an accredited coder and listen as I tell you about a potential workload awaiting me tomorrow in an ‘average’ acute NHS Trust. I will spend the majority of my working hours interrogating massive swathes of source documentation across multiple systems, potentially including paper inpatient notes (yes) to establish an accurate picture of the patients health and their healthcare stay. I will aim to do this for as many patients as possible and the entire process is typically time consuming and hence inefficient.
Now imagine also that I am focusing my working hours on this day to code something like daycase endoscopy patients…
“Patient one — an OGD. Patient two — an OGD. Patient three — a colonoscopy! Patient four — an OGD.”
This skilled clinical discipline, from a coding perspective, is not as engaging as say a long stay inpatient with multiple medical issues. This monotony is a necessity in a manual coding process, our coder needs to code the entirety of the activity and our coder does it with skill and pride, but it is tiresome and tends to burn the mind out, particularly during periods of heightened inpatient activity (not in the NHS surely?).
Let’s revisit the manual coding process overview from earlier but this time I’ll use a RAG status to show you where our pressure points are as a service…I’ll “tell you where it hurts”.
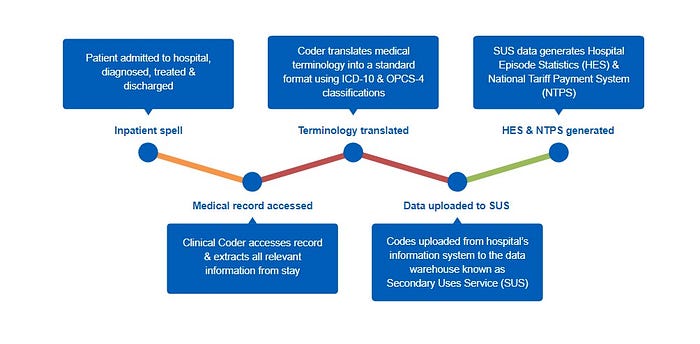
The manual coding process is subject to frequent inefficiencies from the point of patient discharge, the receipt and collation of the medical documentation and the translation and assignment of classification codes.
Consider then in summary these three points:
- The output of a clinical coding function is important to the functioning of a Trust.
- The relative effort and cost involved in producing coders is high and the mundane aspects of their role in a manual coding process are innately linked to workforce attrition.
- A typical manual coding process in an NHS Trust is at best inefficient.
How do we tackle these issues? What means of attack are available to us and have been available elsewhere for quite some time?
The automation of coding…
In my next post I’ll discuss in general detail the potentials around automating coding, the backdrop of work carried out by colleagues in this field and our efforts so far at Kettering General.
